1.向表中插入数据操作
INSERT into user_info values(1, 'fqq', '女') -- 插入数据,在user_info表中按照字段顺序进行插入数据,此时插入的字段不能少INSERT into user_info(id, names) VALUES(2, 'why') -- 插入数据,指定插入到user_info表中的id和name字段中,前提是剩余没有被插的字段必须有默认值INSERT into user_info(id, names) VALUES(3, 'w'), (4, 'wh') -- 一次插入多条数据INSERT into user_info(names, sex) select `names`, sex from user_info where id = 1; -- 从user_info表中查询出来id为1的那一条记录,只要这条记录的name和sex字段,然后插入到user_info中
2.删除表中的数据
DELETE form user_info where id = '4'; -- 删除user_info表中id为的记录。删除指定的数据DELETE form user_info; -- 删除user_info表中的所有数据。如果表中有自增主键,如递增到10了,使用这个语句删除表中的所有数据后,再插入数据的时候,其递增主键的值为11。 不会删除递增主键所记录到哪个值了
TRUNCATE user_info; -- 删除user_info表中的所有数据。删除的速度比delete form user_info快。 会删除自增主键的信息。再插入数据的时候递增会从1开始。其与delete 删除表数据的区别还有很多,后面再说
4.修改更新表中的数据
update user_info set sex = '男' where id = '2'; -- 修改更新id为2的那条记录的sex为男update user_info set sex = '女', names = 'xiaoqiao' where id = '2'; -- 修改更新id为2的那条记录的sex为女,names为xiaoqiao
5.查询表中的数据
5.1单表查询
5.1.1创建一张表先。
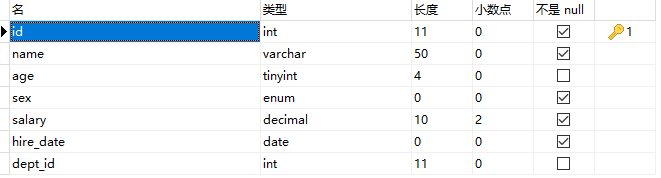
(1)autp_increment是自增属性。PROIMARY KEY(id)意思为id设置为主键表不可重复。 ENGINE=INNODB是设置搜素引擎。auto_increment=13表示自增属性从13开始自增。charset=utf8表示编码为utf-8
create table peron ( id int(11) not null auto_increment, name varchar(50) not null, age tinyint(4) default '0', sex enum('男','女','人妖') not null default '人妖', salary decimal(10, 2) not null DEFAULT '250.00', hire_date date not null, dept_id int(11) default null, PRIMARY KEY (id)) ENGINE=INNODB auto_increment = 13 DEFAULT CHARSET = utf8; (2)创建数据
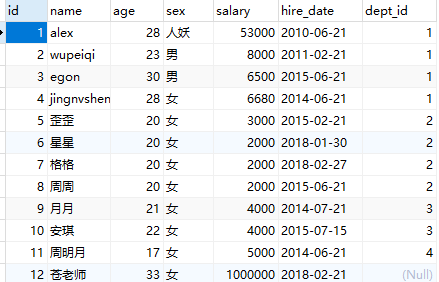
# 教学部insert into peron values('1', 'alex', '28', '人妖', '53000.00', '2010-06-21', '1');insert into peron values('2', 'wupeiqi', '23', '男', '8000.00', '2011-02-21', '1');insert into peron values('3', 'egon', '30', '男', '6500.00', '2015-06-21', '1');insert into peron values('4', 'jingnvshen', '28', '女', '6680.00', '2014-06-21', '1');# 销售部insert into peron values('5', '歪歪', '20', '女', '3000.00', '2015-02-21', '2');insert into peron values('6', '星星', '20', '女', '2000.00', '2018-01-30', '2');insert into peron values('7', '格格', '20', '女', '2000.00', '2018-02-27', '2');insert into peron values('8', '周周', '20', '女', '2000.00', '2015-06-21', '2');#市场部insert into peron values('9', '月月', '21', '女', '4000.00', '2014-07-21', '3');insert into peron values('10', '安琪', '22', '女', '4000.00', '2015-07-15', '3');# 人事部insert into peron values('11', '周明月', '17', '女', '5000.00', '2014-06-21', '4');# 鼓励部insert into peron values('12', '苍老师', '33', '女', '1000000.00', '2018-02-21', null); (3)此时表结构与表内容为
5.1.2简单的数据查询
select * from person; -- 查询所有数据select name,sex from person; -- 查询person表中的所有name和sexselect name, sex as '性别' from person; -- as的意义为sex字段起别名,原来的sex名还是可以用的select salary + 200 from person; -- 查询person表中所有的salary记录,查询出来后+200后显示,没有修改原数据记录select distinct age from person; -- 去重查询person表中的所有age记录。disinct关键字认为被修饰的所有字段都重复了,才认为重复
5.1.3条件查询
条件查询使用where关键字对简单查询的结果集进行过滤
(1)比较运算符:> < <= >= = <>(1=)
select * from person where age > 20; -- 查询person表中age大于20的数据select * from person where age <= 20; -- 查询person表中age小于等于20的数据SELECT * from person where age <>20; -- 查询person表中age不等于20的数据select * from person where age != 20; -- 查询perso表中age不等于20的数据
(2)null关键字:is null,not null
select * from person where dept_id is null; -- 查询person表中dept_id字段为null的记录select * from person where dept_id is not null; -- 查询person表中dept_id字段不为null的记录select * from person where name = ''; -- 查询person表中name为空字符的记录
(3)逻辑运算符:and or ,多个条件时,需要使用逻辑运算符进行连接
select * from person where age = 23 and salary = 29000; -- 查询person表中age等于23 并且 salary收入为29000的记录select * from person where age = 23 or salary = 29000; -- 查询person表中age等于23 并且salary等于29000的记录
person where not(age = 23 and salary = 29000); -- 查询person表中age=23并且salary=29000意外的其他记录
5.1.4区间查询
关键字between 10 and 20;表示获得10到20区间的内容
select * from person where age between 18 and 20; -- 查询person表中age 18到20的记录,前后包含
5.1.5集合查询
关键字:in,not null
select * from person where id =1 or id = 3 or id = 5; -- 查询person表中id为1,3,5的记录select * from person where id in(1, 3, 5); -- 查询person表中id为1,3,5的记录SELECT * from person where id not in(1, 3, 5); -- 查询person表中id不为1,3,5的记录
5.1.6模糊查询
关键字:like,not like
%:任意多个字符
_:只能是单个字符
select * from person where name like '%e%'; -- 查询person表中name字段中含e的记录,包含指定参数select *from person where name like '%e'; -- 查询person表中name字段中以e结尾的记录,以什么结尾select *from person where name like 'e%'; -- 以什么开头select * from person where name like '__e%'; -- 查询表中name字段中第三个字符含有e的记录。 _表示占位符的意思,一个_占位一个字符。select * from person where name like '__'; -- 查询person表中name字段中占有两个字符的记录
5.1.7排序查询
关键字:ORDER BY 字段1 DESC,字段2 ASC
ORDER BY 和where一起用时,必须写在where 条件的后面
select * from person ORDER BY salary; -- 查询person表中的所有数据,记录按照salary进行正序(从小到大排序)。排序查询select * from person ORDER BY salary asc; -- 查询person表中的所有数据,记录按照salary进行正序(从小到大排序)。排序查询select * from person ORDER BY salary desc; -- 查询person表中的所有数据,记录按照salary进行倒序(从大到小排序)。排序查询select * from person where age > 20 ORDER BY salary desc; -- 查询person表中age>20的记录,并且按照salary进行倒序排序select * from person ORDER BY name desc; -- 查询person表中name的数据,倒序排序,中文不支持进行排序select * from person ORDER BY convert(name using gbk) asc; -- 中文要想进行排序,要加入convert(name using gbk)表示name字段使用gbk进行编码查询(此时中文也按照首字母拼音的顺序排序)。这句话意思为查询person数据,以name字段进行正序排序查询